Building a Production-Ready MCP Server with OAuth, TypeScript, and Our Battle Scars
Dive into our journey building a secure, multi-tenant MCP server using OAuth 2.0, TypeScript, and Firestore. Learn from our architectural pivots, security deep-dives, and real-world lessons in enabling AI agent capabilities.

The dream of "AI Native" applications, where intelligent agents autonomously manage tasks and even orchestrate other agents, is rapidly materializing. For us, the Model Context Protocol (MCP) is the key—the universal translator enabling our AI to wield a powerful, secure toolkit of backend services. Our mission was ambitious: build an MCP server allowing AI agents to manage their own ecosystem, including other agents and their data integrations, all within a multi-tenant environment.
This article chronicles our journey: the architectural pivots forced by evolving standards, the security deep-dives that led us to OAuth 2.0, the pragmatic shift from Python to type-safe TypeScript, and the hard-won lessons building this system on Google Firestore. Expect not just the "what" and "how," but the crucial "why," complete with the dead-ends, "aha!" moments, and a few battle scars that shaped our path.
OAuth as Our Cornerstone
When AI agents can modify data across third-party apps and manage each other, security isn't a feature; it's the absolute bedrock.
The Initial Stumble: API Keys & SDK Hurdles
Our first foray used API keys in request headers. While seemingly simple, it quickly exposed limitations. The Python MCP SDK at the time didn't offer straightforward access to these headers or the underlying Starlette request object within tool handlers—a critical blocker for implementing proper authorization logic. This pushed us towards experimenting with a forked, version of the SDK waiting to be merged into the main branch, a clear indicator of an unconventional path we might later regret going down.
Interoperability, Standards, and OAuth 2.0
We briefly considered token query parameters (less secure) but the real turning point came when envisioning external MCP clients. How could they securely and reliably integrate if we relied on a custom, patched authentication scheme? The answer became crystal clear: OAuth 2.0. It's the only authentication method specified in the official MCP standard, inherently supports dynamic client registration (vital for scaling), and guarantees the broadest compatibility. This wasn't just a security upgrade; it was a strategic commitment on our part to the MCP ecosystem's health and our server's accessibility.
The OAuth 2.0 Version
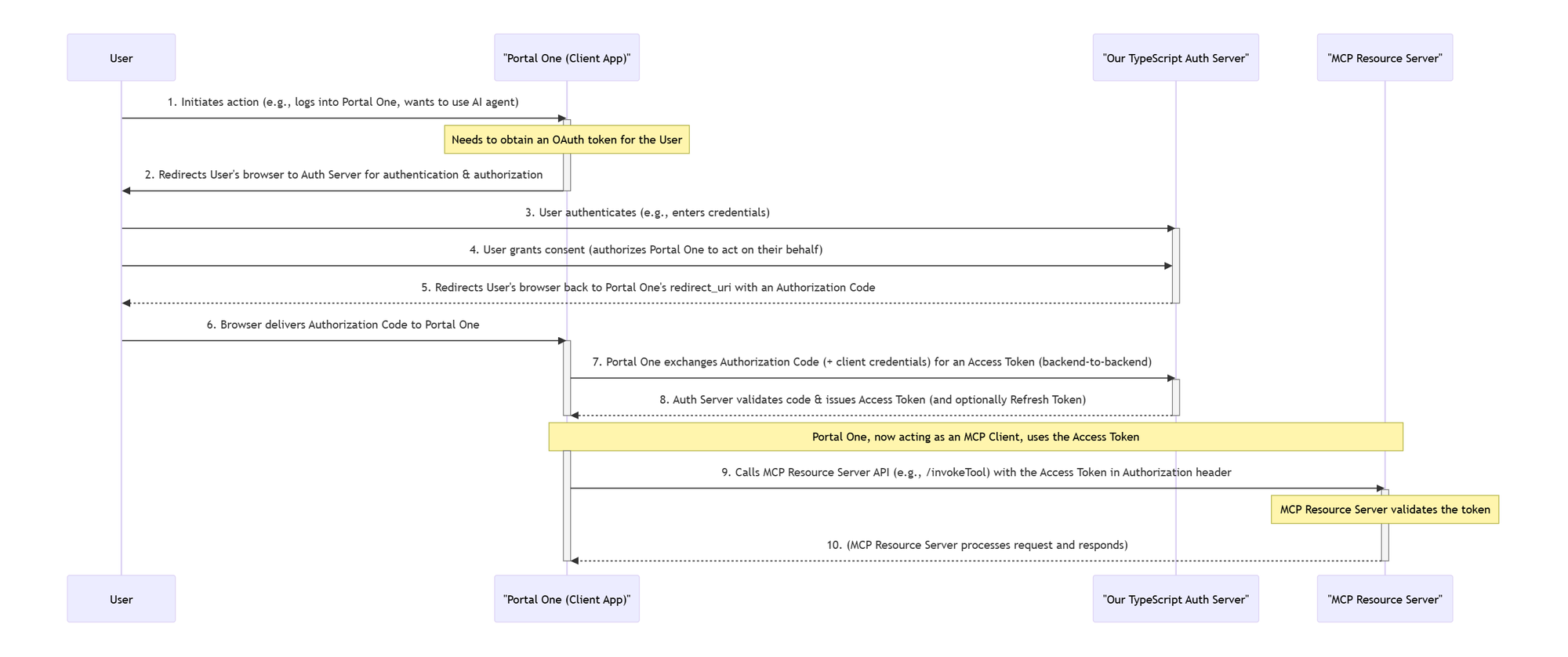
redirect_uris; and always use PKCE for public clients to prevent authorization code interception.Architectural Evolution: From Python Dreams to TypeScript Realities
Our server architecture wasn't a pre-defined blueprint; it was an iterative response to technical challenges, SDK capabilities, and our own evolving understanding.
The Python Starting Line and the User Session Issue
We initially envisioned a rapid deployment using the Python MCP SDK and FastMCP, with the OAuth authorization server co-located with the resource server (our MCP server). The critical roadblock: our Python MCP server, as a distinct service, had no access to our main application's (Portal One) user sessions. This made linking an authorizing user to their Portal One account and, crucially, their workspace permissions, nearly impossible without re-implementing session management in Python—a significant and undesirable detour.
The TypeScript Pivot: Embracing a More Mature Ecosystem
The pragmatic solution was to host the OAuth endpoints on our existing TypeScript application server, which already managed user sessions and authentication. After a bit of "hacking" the Python SDK's OAuthServerProvider to work as a proxy to correctly target these new TypeScript auth routes, we achieved a fragile success. However, the next hurdle was accessing the validated token's associated user ID within the Python tool handlers.
As we researched solutions, we discovered the TypeScript MCP SDK had matured significantly for our use case. It offered:
- An
authInfoobject directly in the tool context, providing clean access to token details. - A
ProxyOAuthServerclass, specifically designed for architectures where the OAuth authorization server is separate from the MCP resource server. This was the decisive moment: we migrated the entire MCP server to TypeScript.
Our Core Technology Stack
- MCP TypeScript SDK: The backbone for protocol implementation.
- TypeScript & Node.js: For type-safe, efficient server-side logic.
- Google Firestore: Our existing, scalable, and secure NoSQL database for user profiles, OAuth tokens, tool definitions, and all workspace-specific data. Its real-time capabilities and flexible data model were invaluable.
- Zod: Already integral to our Portal One codebase, Zod was the natural choice for defining input/output schemas for tools. This enabled robust runtime validation and, critically, automatic JSON schema generation for LLM consumption via the MCP SDK.

Bringing It All Together
Let's walk through a concrete example: An AI agent, operating within "Workspace Alpha" for "User Jane," needs to retrieve details for a specific memory item.
Step 1 - LLM Intent & Tool Selection
- User Jane asks the agent: "Can you remind me about the 'Q3 Marketing Plan' memory?"
- The LLM, having access to the agent's tools (including their JSON schemas), determines it needs to use the
get_memorytool. It knows theget_memorytool requires bothworkspace_idandmemory_idarguments. - The
workspace_idmight be defaulted to "Workspace Alpha" in the schema provided to the LLM (more on this later). The LLM extracts "Q3 Marketing Plan" and, through prior knowledge or another tool call (e.g.,find_entities_by_title), resolves it tomemory_id: "mem_123".
// Headers: { "Authorization": "Bearer <JANE_OAUTH_TOKEN>" }
{
"name": "get_memory",
"arguments": {
"workspace_id": "Workspace Alpha", // or defaulted
"memory_id": "mem_123"
}
}Step 2 - MCP Server: Authentication & Authorization
- The request hits our Node.js/TypeScript MCP server.
- The MCP SDK middleware validates the
Authorization: Bearer <JANE_OAUTH_TOKEN>header format and extracts the token. It makes this token available inreq.authInfo.token, and gives us theextraproperty for our own custom properties.
import { requireBearerAuth } from '@modelcontextprotocol/sdk/server/auth/middleware/bearerAuth.js';
// Middleware to handle bearer token authentication and
// inject user data into the request context.
const tokenMiddleware = requireBearerAuth({
requiredScopes: ['default'],
resourceMetadataUrl: new URL(OAUTH_ISSUER_URL).toString(),
verifier: {
verifyAccessToken: async (token: string) => {
// Here you would typically verify the token with your OAuth server
// For this example, we will just return a mock user data.
const tokenRes = {
user_id: '12345',
client_id: 'client-123',
scope: ['default'],
};
return {
token,
clientId: tokenRes?.client_id,
scopes: tokenRes?.scope,
// Include any extra data you want to use in the tool handlers
extra: {
userId: tokenRes?.user_id,
},
};
},
},
});
app.use(
'/mcp',
tokenMiddleware,
mcpRoutes,
);- The
get_memorytool's handler is wrapped by ourwithWorkspaceAccessHOC. - Token Validation: The HOC uses the
userIdprovided when we parsed the auth header in theProxyOAuthServerProviderimplementation. It then fetches Jane's user document, which includesworkspaces: ["Workspace Alpha", "Workspace Beta"].
export function withWorkspaceAccess<T extends z.ZodTypeAny>(
db: Firestore,
inputSchema: T,
handler: (
args: z.infer<T>,
req: RequestHandlerExtra<ServerRequest, ServerNotification>,
) => Promise<CallToolResult>,
) {
return async (
args: z.infer<T>,
req: RequestHandlerExtra<ServerRequest, ServerNotification>,
) => {
// We placed this here in our ProxyOAuthServerProvider implementation:
const userId = req.authInfo?.extra?.userId || ''
if (!userId) throw new Error('No user ID found in token.');
const hasAccess = await checkWorkspaceAccess(db, userId, args.workspace_id);
if (!hasAccess)
throw new Error('You do not have access to this workspace.');
return handler(args, req);
};
}- Workspace Access Check: The HOC retrieves
args.workspace_id("Workspace Alpha"). It then callscheckWorkspaceAccess(db, "jane_doe", "Workspace Alpha", janeUserDocument). Since "Workspace Alpha" is in Jane'sworkspaceslist, this returnstrue.
export async function checkWorkspaceAccess(
db: Firestore,
userId: string,
workspaceId: string,
): Promise<boolean> {
const userDoc = await db.collection('users').doc(userId).get();
if (!userDoc.exists) return false;
const userData = userDoc.data();
return (
Array.isArray(userData?.workspaces) &&
userData.workspaces.includes(workspaceId)
);
}- All checks pass. The HOC now calls the actual
get_memoryhandler, passing the validatedargsand Jane'suserId.
// Simplified get_memory handler logic
async function getMemoryHandler(args, req, userId) {
const memoryRef = db
.collection('workspaces')
.doc(args.workspace_id) // "Workspace Alpha"
.collection('memories')
.doc(args.memory_id); // "mem_123"
const memorySnap = await memoryRef.get();
if (!memorySnap.exists) {
throw new Error(`Memory ${args.memory_id} not found in workspace ${args.workspace_id}.`);
}
const memoryData = memorySnap.data();
// Convert Firestore Timestamps to JS Dates
const output = {
...memoryData,
created_at: memoryData.created_at.toDate(),
updated_at: memoryData.updated_at.toDate()
};
return { content: [{ type: 'text', text: JSON.stringify(output) }] };
}Step 3 - LLM Processes Result & Responds to User
The LLM receives the JSON, parses the memory details, and might respond to Jane: "Okay, Jane, the 'Q3 Marketing Plan' memory contains details about our upcoming initiatives, created on March 15th. It includes sections on..."
{
"content": [{
"type": "text",
"text": "{\n \"id\": \"mem_123\",\n \"title\": \"Q3 Marketing Plan\",\n \"created_at\": \"2025-03-15T10:00:00.000Z\",\n \"updated_at\": \"2025-03-16T14:30:00.000Z\"\n}"
}]
}The Complete Flow
This end-to-end flow, secured by OAuth and contextualized by workspace_id, forms the backbone of our agent interactions.
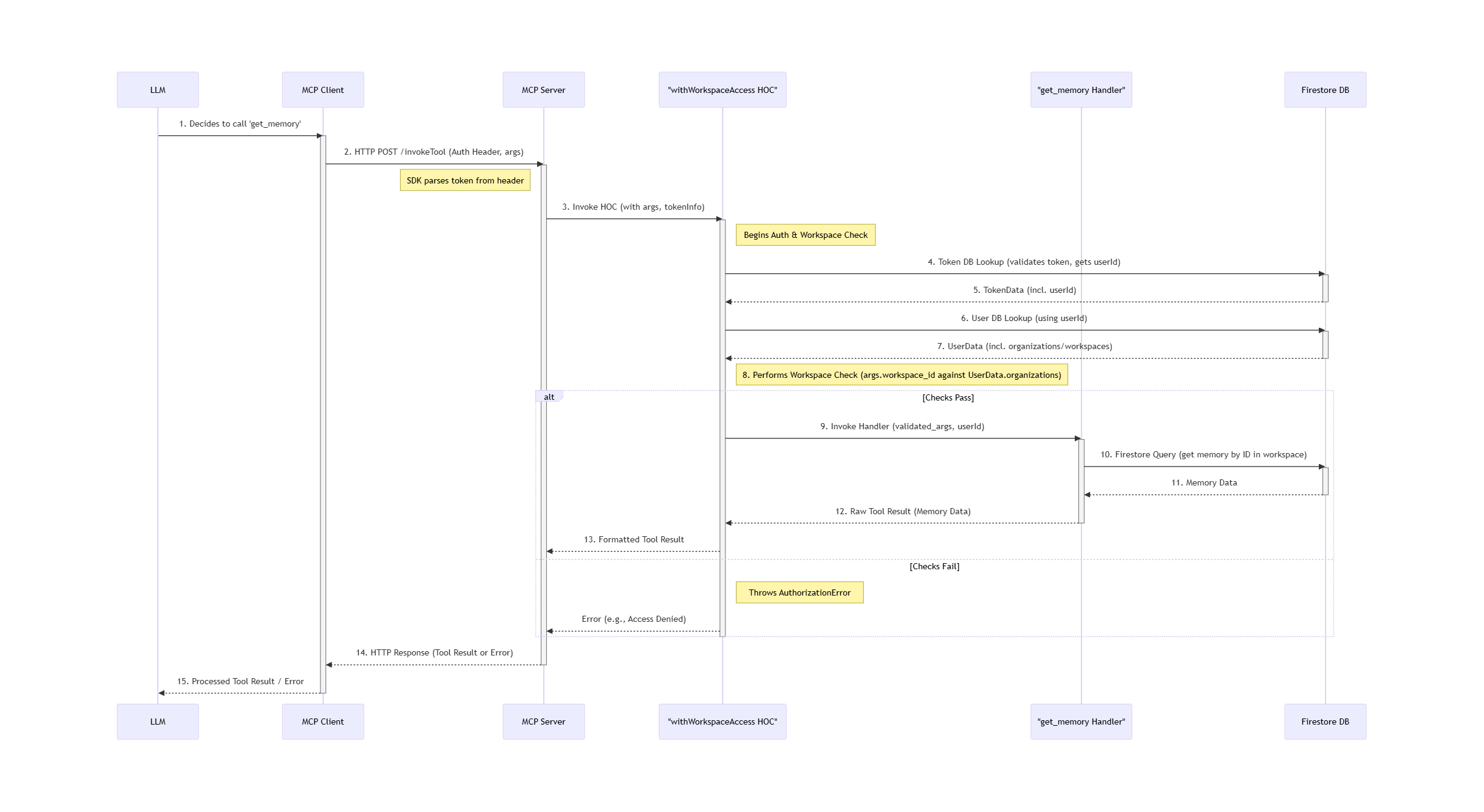
withWorkspaceAccess Higher-Order Component (HOC) performing authentication and workspace authorization checks against Firestore, to the specific get_memory tool handler executing its logic and querying the database, and finally the response returning to the LLM. It highlights the critical security and context validation steps within our server architecture.Our Toolkit for Robustness
Building reliable tools required a multi-faceted approach.
Our Schema and Validation Powerhouse
Zod was already indispensable before since we use it for form validation in our frontend. Now it doubles up to do even more work in our MCP server:
- LLM Schema Generation: The MCP TypeScript SDK leverages Zod schemas to automatically produce the JSON Schemas LLMs require to understand tool parameters and structure calls correctly.
- Robust Runtime Validation: Incoming tool arguments are validated against these Zod schemas. If validation fails, our error handling allows the agent to potentially correct its call.
- Type Safety & Inference: TypeScript types derived from Zod schemas ensured consistency between expected and actual data structures, catching potential issues at compile time.
Error Handling: throw Error() for Clarity and SDK Synergy
We transitioned from returning error strings (a common pattern in simpler Python scripts) to consistently using throw new Error("Descriptive message here") for all exceptional cases (e.g., "Entity not found," "Invalid input," "Authorization failed"). The MCP SDK gracefully catches these, packaging them into a standard ToolCallResponse object with an isError: true flag. This simplified our tool logic significantly and provided a uniform error reporting mechanism to the client/LLM.
Firestore Timestamps: The .toDate() Discipline
A hard-learned lesson: Firestore Timestamp objects are not directly JSON-serializable as JavaScript Date objects. Early on, this caused frustrating frontend issues and required downstream services to perform conversions. Our unwavering rule now: always call .toDate() on timestamp fields immediately after fetching from Firestore and before including them in any API response or tool output. This prevents leaky abstractions and ensures predictable data formats.
Utility Functions: DRY Principles in Action
Tools like get_agent or get_conversation often need to fetch multiple related entities (memories, forms, tables, etc.). To avoid rampant code duplication, we developed generic utilities:
fetchResourceList: Takes a workspace ID, collection name, array of document IDs, and a list of fields to return. It handles the batch fetching and projection efficiently.fetchModel: Fetches model details and crucially, abstracts the logic for masking sensitive data likeapi_keys withincompletion_params. These utilities significantly slimmed down our tool handlers (often by 5-10 lines per related resource in complex tools) and centralized common data access patterns, making maintenance far easier.
// Example: Using fetchResourceList in a tool
// Inside a handler wrapped by withWorkspaceAccess:
const agentData = await agentRef.get().then(snap => snap.data());
if (agentData) {
const [memories, forms] = await Promise.all([
fetchResourceList(db, args.workspace_id, 'memories', agentData.memories || [], ['id', 'title', 'description']),
fetchResourceList(db, args.workspace_id, 'forms', agentData.forms || [], ['id', 'table_id'])
]);
result.memories = memories;
result.forms = forms;
}Standardizing Entity Types
For shared concepts like ResourceType, EntityType, Status, and FieldType (for table schemas), we adopted a consistent pattern using TypeScript's string literal unions (via as const) paired with Zod's z.enum():
// utils/types.ts (example for FieldType)
export const FieldTypes = ['string', 'number', 'date', 'boolean'] as const;
export type FieldType = (typeof FieldTypes)[number]; // Creates "string" | "number" | ...
export const fieldTypeSchema = z.enum(FieldTypes); // Zod schema for validation
export interface Field {
name: string;
type: FieldType;
id: string;
}
export const fieldSchema = z.object({
name: z.string(),
type: fieldTypeSchema,
id: z.string(),
});This provides a single source of truth for both TypeScript's static type checking (catching typos at compile time) and Zod's runtime validation, significantly improving developer experience and code robustness.
Smarter Agents, Shorter Prompts
With workspace_id now a required argument for most tools, how could agents seamlessly operate within their designated workspace without cluttering their system prompts? System prompts can be unreliable for such specific, recurring data; LLM adherence varies, and long prompts can degrade performance. Tool schemas, however, offer a more structured and reliable way to provide this context.
Our solution: When adding the available tools to the LLM call for each agent response, we dynamically patch the JSON schema of each tool. If a tool's inputSchema includes a workspace_id property, we inject a "default": "AGENT_NATIVE_WORKSPACE_ID" value into the inputSchema, where AGENT_NATIVE_WORKSPACE_ID is the actual ID of the workspace the requesting agent itself belongs to.
Impact on Agent Behavior
Injecting default values into the tool schemas prior to adding them to the LLM call gives us the opportunity to add context in a structured way.
Before (No Schema Default):
- Agent is in "Project Zeta."
- User: "List tables in Project Zeta." -> Agent correctly calls
list_tables({ workspace_id: "Project Zeta" }). - User (later): "Now, list memories." -> Agent, having "forgotten" the explicit context or not seeing it as relevant for this new request, might call
list_memories({}). - Result:
Tool call failed: workspace_id is required.The agent might then try to ask the user for the workspace or give up.
After (Schema Default Injected):
- Agent is in "Project Zeta." The
list_memoriestool schema it received hasproperties.workspace_id.default: "Project Zeta". - User: "List tables in Project Zeta." -> Agent calls
list_tables({ workspace_id: "Project Zeta" }). - User (later): "Now, list memories." -> Agent calls
list_memories({}). The default workspace idProject Zetais injected into the tool schema prior to being sent to the LLM and marked as the default. - The LLM sees the default
workspace_idin its given tool schema and chooses to include in the generated tool call arguments. - MCP Server receives:
list_memories({ workspace_id: "Project Zeta" }). - Result: The
withWorkspaceAccessHOC validates Jane's access to "Project Zeta," the tool executes successfully. The agent responds: "Here are the memories in Project Zeta..." This significantly improved the reliability of contextual operations and reduced frustrating "I need more information" loops from the agent.

Lessons From the Trenches
No significant engineering effort is without its share of "learning opportunities":
- The Evolving Standard: We initially built our server using the
/sse(Server-Sent Events) transport for streaming, only for it to be deprecated from the MCP standard less than six months later! This underscored the need to stay agile, build with abstractions that can accommodate change, and be prepared for breaking changes in a nascent ecosystem. - Python SDK Growing Pains: The early need to use a fork of the Python SDK to access request headers for API key auth was a significant early hurdle. It was a major motivator for exploring and ultimately adopting the TypeScript SDK, which, for our specific auth-server separation needs, was more mature at the time.
- The OAuth Chicken-and-Egg: Setting up the separate OAuth server (on our main TypeScript app) and getting the resource server (our MCP server) to correctly proxy/validate tokens involved a lot of trial and error with configurations, understanding the nuances of the
ProxyOAuthServerin the SDK, and ensuring secure communication between the two.
Key Learnings:
- Embrace the Bleeding Edge (with Caution): Working with new standards like MCP is exciting but requires vigilance. Actively monitor GitHub issues, participate in community discussions, and design for adaptability.
- Type Safety is Non-Negotiable for Complexity: TypeScript + Zod saved us countless hours by catching errors statically and ensuring data integrity at runtime, especially as the number of tools and their parameters grew.
- Iterate, Abstract, Refine: Start with the simplest thing that could work, then refactor to create abstractions (like HOCs and utility functions) as patterns emerge. Don't over-engineer upfront.
- Client-Side Feedback is King: Using our own Portal One app as the primary MCP client provided an incredibly fast and realistic development and testing loop. Dogfooding is invaluable.
- Performance & Scalability (Initial Thoughts): While not yet a bottleneck for our current load, we're mindful of Firestore query patterns (e.g., avoiding large, unindexed scans by ensuring queries are highly selective). For future scaling, we'd consider Firestore indexing strategies, optimizing data structures, and potentially horizontal scaling of the Node.js MCP server instances. Cold starts for serverless deployments (if we were to go that route for some tools) would also be a key performance consideration.
What We'd Do Differently
Adopt TypeScript SDK Sooner for Auth Needs: Had we fully grasped the TypeScript SDK's capabilities for separate auth/resource server patterns earlier, we might have saved the initial Python development cycle for the MCP server itself.
The Path Forward
Our MCP server is now a powerful, secure, and extensible platform. Immediate next steps include:
- Dynamic Tool Updates: Implementing support for MCP server-initiated events, so Portal One can automatically sync tool changes without requiring manual user action, making the tool ecosystem truly dynamic.
- Expanding the Toolkit: Continuously adding new, sophisticated tools to enhance agent capabilities based on user needs and emerging AI use cases.
- Granular Permissions & Scopes: Exploring more fine-grained permissions within workspaces for tool usage, potentially tied to more specific OAuth scopes, to further enhance security and control.

Conclusion: Powering the AI Native Future, Securely and Scalably
The journey to this MCP server—from Python experiments and API key workarounds to a type-safe TypeScript implementation with robust OAuth 2.0—has been transformative. The most significant outcome is a flexible architecture supporting multiple, specialized MCP servers, all delegating authentication to a central OAuth provider. This empowers any Portal One user to securely leverage a diverse and growing set of AI-driven tools.
The ability for users to seamlessly and securely "plug in" their own tools, or for us to rapidly deploy new ones, solves a foundational challenge we've faced since Portal One's inception. It's a critical step towards our vision of truly AI Native applications, where intelligent agents are not just assistants, but empowered, autonomous actors in a secure and interconnected digital world.
Full Example Code
We believe in sharing knowledge so we've extracted key components like our withWorkspaceAccess HOC, utility functions, and example tool structures into a public demo repository. Check out the GitHub repository here and star it if you find it helpful!